
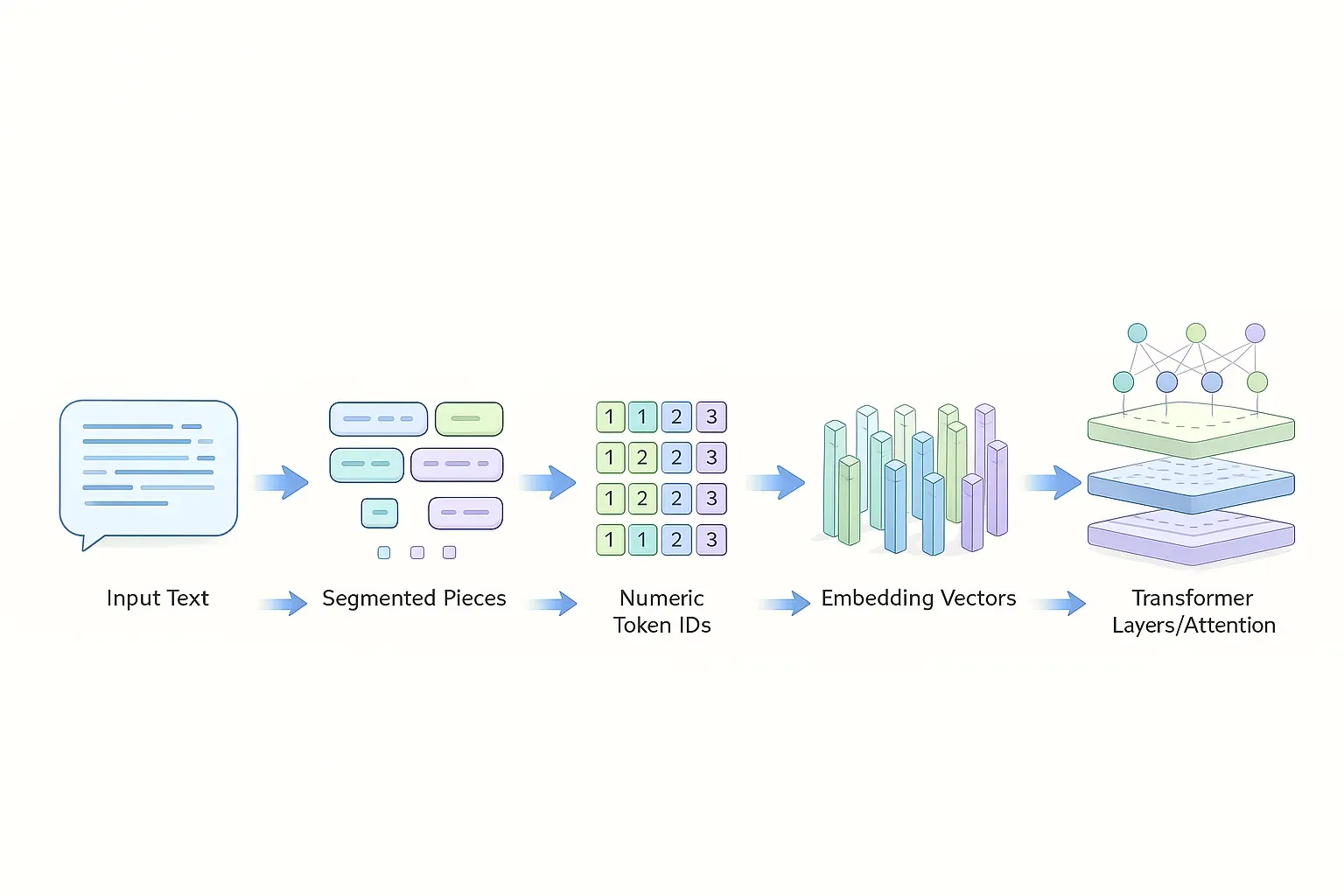
Tokenizacja to proces zamiany tekstu na ciąg identyfikatorów (ID), które model potrafi przetwarzać. Token nie musi być słowem — często jest fragmentem słowa, znakiem interpunkcyjnym lub częścią zapisu bajtowego. Jest kluczowa, bo decyduje o kosztach, limicie kontekstu, jakości generacji i o tym, jak model „widzi” język (także polski).
Dlaczego w ogóle istnieje tokenizacja w modelach językowych?
Tokenizacja istnieje, bo model językowy nie operuje na „literach” ani „słowach” tak jak człowiek. Potrzebuje dyskretnych symboli z ustalonego słownika, które można szybko mapować na liczby i wektory. Tokenizacja to więc most: tekst → ID → matematyka. Od tego mostu zależy koszt, limit kontekstu i stabilność wyników.
Jak token różni się od słowa i litery?
- Słowo to kategoria językowa (np. „przedsiębiorczość”).
- Litera to znak pisma (np. „ł”).
- Token to jednostka techniczna tokenizera — może być:
- całym słowem (
"kot"), - fragmentem słowa (
"przed" + "siębior" + "czość"), - znakiem interpunkcyjnym (
",","("), - albo czymś „dziwnym”, gdy w grę wchodzi zapis bajtowy.
- całym słowem (
W praktyce: tokenizacja jest mapowaniem tekstu na sekwencję ID, np."Ala ma kota." → [1012, 532, 8841, 13] (to tylko ilustracja; ID zależą od modelu).
Dlaczego model nie „widzi” liter jak człowiek?
Model to nie edytor tekstu. W środku działa na macierzach i wektorach. Żeby przetwarzać język wydajnie, potrzebuje:
- ograniczonego alfabetu symboli (słownik tokenów),
- szybkiego kodowania wejścia (ID),
- stabilnego procesu uczenia (te same zasady dla całego korpusu).
Tokenizacja upraszcza problem: zamiast nieskończonej liczby możliwych napisów, mamy skończony zestaw tokenów i reguły ich składania.
Dlaczego ten sam tekst może mieć różną liczbę tokenów? (2–3 przykłady)
Różni tokenizery (i słowniki) tną inaczej — dlatego liczba tokenów zależy od konkretnego modelu.
Przykład 1: spacja i interpunkcja
- „ChatGPT” vs „Chat GPT”
- jeden tokenizer może mieć token dla „ChatGPT”, inny potnie na „Chat” + „G” + „PT”.
Przykład 2: polskie znaki i rzadkie zlepki
- „zażółć” i „zazolc”
- zapis bez ogonków może być częstszy w danych, więc czasem bywa „tańszy” tokenowo (ale to nie reguła).
Przykład 3: liczby i identyfikatory
- „2025-12-14” vs „14 grudnia 2025”
- jedne modele lubią wzorce liczbowe, inne tną je na drobne kawałki.
Wniosek: jeśli optymalizujesz koszt lub limit kontekstu, sprawdzaj tokeny na docelowym tokenizerze, a nie „na oko”.
Jak działają najpopularniejsze metody tokenizacji (BPE, WordPiece, Unigram)?
Większość współczesnych LLM używa tokenizacji „subword” — dzieli słowa na fragmenty, które da się składać jak klocki. Dzięki temu słownik nie musi zawierać wszystkich słów świata, a model nadal potrafi obsłużyć neologizmy, odmianę i nazwiska. Różnice między BPE, WordPiece i Unigram dotyczą tego, jak buduje się słownik i jak wybiera podział.
Co oznacza „subword” i po co jest słownik?
Subword (pod-słowo) to fragment, który pojawia się często i jest użyteczny jako element składowy.
Zamiast trzymać w słowniku „przedsiębiorczość” jako całość, trzymasz np. „przed”, „siębior”, „czość”.
Słownik tokenów daje kompromis:
- mniejszy słownik → szybszy model, ale częstsze cięcie na drobno,
- większy słownik → mniej tokenów na tekst, ale więcej parametrów w warstwie embeddingów.
Jak działa BPE (Byte Pair Encoding) w intuicji?
BPE zaczyna od prostych jednostek (często znaków) i iteracyjnie scala najczęstsze pary sąsiadujących symboli.
- Na starcie:
p r z e d s i ę ... - Jeśli „pr” jest częste → scala do „pr”
- Jeśli „przed” jest częste → scala kolejne pary aż powstanie „przed”
Efekt: powstaje słownik fragmentów, które statystycznie „opłaca się” mieć jako całość.
Jak działa WordPiece w intuicji?
WordPiece jest podobny do BPE, ale w praktyce często opisuje się go jako wybór tokenów, które maksymalizują prawdopodobieństwo danych przy danym słowniku. W wielu implementacjach różnice względem BPE są subtelne, ale ważny jest cel: znaleźć taki zestaw subwordów, by teksty kodowały się „sensownie” i stabilnie.
Jak działa Unigram (np. SentencePiece Unigram) w intuicji?
Unigram startuje z dużą listą kandydatów na tokeny i traktuje tokenizację jak problem probabilistyczny:
- mamy wiele możliwych podziałów zdania,
- wybieramy ten, który ma najlepszy wynik wg modelu (np. największe prawdopodobieństwo),
- słownik jest „przycinany” przez usuwanie tokenów mało przydatnych.
To podejście często dobrze radzi sobie z językami o bogatej morfologii.
Mini-tabela: kiedy która metoda ma sens?
| Metoda | Intuicja budowy słownika | Mocne strony | Typowe zastosowania |
|---|---|---|---|
| BPE | scala najczęstsze pary | prosta, szybka, skuteczna | LLM-y, gdzie liczy się praktyka i wydajność |
| WordPiece | optymalizuje użyteczność tokenów (prawdopodobieństwo) | stabilne cięcia, dobre dla NLP pipeline | modele „BERT-owe”, klasyczne NLP |
| Unigram | wybiera najlepszy podział z wielu (probabilistycznie) | elastyczność, często dobra dla morfologii | SentencePiece, wielojęzyczne modele |
Najważniejsze: dla użytkownika LLM różnice metod są mniej istotne niż fakt, że tokenizer jest częścią modelu — i trzeba go traktować jak „specyfikację wejścia”.
Co to jest byte-level tokenization i czemu dziwnie tnie polski?
Byte-level tokenization schodzi poziom niżej niż znaki i subwordy: w razie potrzeby potrafi kodować tekst jako bajty (bytes). To gwarantuje, że każdy możliwy zapis da się ztokenizować bez „unknown token”. Ceną jest czasem „dziwne” cięcie, szczególnie w językach z diakrytykami i bogatą odmianą, jak polski.
Jak diakrytyki (ą/ę/ł/ś/ż/ź/ć/ń) wpływają na cięcie?
Polskie znaki są w UTF-8 kodowane jako wielobajtowe sekwencje. Jeśli tokenizer nie ma dobrych, częstych tokenów obejmujących całe polskie fragmenty, może:
- rozbić słowo na mniejsze subwordy,
- a w skrajnym przypadku oprzeć się na bajtach (co wygląda jak „poszarpanie”).
W praktyce nowoczesne tokenizery wielojęzyczne zwykle mają sporo polskich kawałków, ale nadal: rzadkie formy fleksyjne i zlepki potrafią puchnąć tokenowo.
Co się dzieje z odmianą, zlepkami, nazwami własnymi i anglicyzmami? (5 przykładów PL)
Poniżej masz krótkie, praktyczne przykłady tego, co typowo może się wydarzyć (konkretny podział sprawdzisz kodem w sekcji o liczeniu tokenów):
- „zażółć”
- diakrytyki + rzadkość → tokenizer może nie mieć gotowego tokenu na całość, więc potnie na 2–5 części.
- „przeksięgowania”
- długi rdzeń i sufiksy → często tnie na rdzeń + końcówki (
"prze","księg","owania"itd.).
- „Rzeczpospolitej”
- nazwa własna w odmianie → bywa cięta inaczej niż „Rzeczpospolita”, bo końcówka „-ej” może nie kleić się statystycznie.
- „AI-owy” / „promptować”
- anglicyzm + polska fleksja → hybrydy często są rozbijane mocniej, bo to „nowa” mieszanka wzorców.
- „Kwiecień2025”
- litery + liczby bez separatora → tokenizery często tną to na segmenty alfanumeryczne, a czasem bardzo drobno.
Czy da się „naprawić” polskie cięcie?
Masz trzy dźwignie:
- dobór modelu (różne modele mają różne słowniki),
- preprocessing tekstu (np. konsekwentne spacje, myślniki, format liczb),
- własny tokenizer / fine-tuning (w praktyce: rzadziej, bo kosztowne).
Na co dzień wygrywa zasada: używaj tego samego tokenizera co model i testuj na swoich danych.
Specjalne tokeny: BOS/EOS, PAD, SEP i tokeny systemowe — po co są?
Specjalne tokeny to znaczniki sterujące, które nie są „normalnym tekstem”, tylko sygnałami dla modelu: gdzie zaczyna się sekwencja, gdzie kończy, czym oddzielić segmenty i czym wypełnić batch. W chatowych LLM dochodzą tokeny ról (system/user/assistant). Błędy w ich użyciu potrafią zepsuć jakość bardziej niż „zły prompt”.
Co robią BOS/EOS, PAD i SEP?
- BOS (begin-of-sequence): sygnał „start”.
- EOS (end-of-sequence): sygnał „koniec”; często wpływa na to, czy model „domyka” odpowiedź.
- PAD: wypełnienie do równej długości w batchu (ważne w trenowaniu i inferencji wsadowej).
- SEP: separator segmentów (np. pytanie vs kontekst).
Jak tokeny systemowe działają w modelach chatowych?
W wielu implementacjach rozmowa jest kodowana jako struktura:
- rola + treść + znaczniki granic,
- czasem dodatkowe „instrukcje systemowe” mają priorytet.
Jeśli „udajesz”, że te znaczniki nie istnieją, łatwo pomylisz się w liczeniu tokenów i w tym, czemu model odpowiada inaczej niż oczekujesz.
Jakie są ryzyka w formatowaniu danych?
Typowe błędy:
- brak separatorów między rekordami (model miesza przykłady),
- podwójne BOS/EOS w złym miejscu,
- niewłaściwe maskowanie PAD w treningu (model uczy się „pustki”),
- złe template’y konwersacji (role nie odpowiadają tokenizerowi).
Reguła praktyczna: jeśli fine-tunujesz lub budujesz dataset, korzystaj z gotowych „chat templates” danego modelu — ręczne składanie znaczników to częsta mina.
Tokenizacja a embeddingi — co dokładnie dzieje się w pipeline?
Tokenizacja to dopiero wejście do maszyny. Model nie „rozumie tokenów” jako słów, tylko mapuje ID na wektory (embeddingi), a potem przekształca je przez warstwy transformera, żeby przewidzieć kolejny token. Jeśli chcesz rozumieć koszty i błędy LLM, musisz widzieć tę ścieżkę: tokeny → wektory → uwaga (attention) → predykcja.
Jak wygląda pipeline: tokeny → embeddingi → warstwy → predykcja?
- Tekst trafia do tokenizera.
- Dostajesz ID tokenów (liczby całkowite).
- Każde ID jest mapowane na wektor w tabeli embeddingów (np. 4096 wymiarów).
- Wektory przechodzą przez kolejne warstwy transformera (self-attention + MLP).
- Na końcu model wypluwa rozkład prawdopodobieństwa następnego tokenu: „co najbardziej pasuje dalej?”.
To dlatego mówimy, że LLM to model predykcji kolejnego tokenu.
Dlaczego „token” nie jest „pojęciem”?
Token to jednostka techniczna. „Pojęcie” to coś, co człowiek wiąże z intencją i znaczeniem.
- Token „-ej” może występować w wielu słowach i nie ma samodzielnej semantyki.
- Token „AI” może być nośny znaczeniowo, ale nadal jest tylko symbolem z ID.
Znaczenie w LLM jest rozproszone: wynika z wektorów i ich relacji w kontekście, a nie z tego, że „token = definicja”.
Tokeny w praktyce prompt engineeringu — jak pisać krócej i pewniej?
W prompt engineeringu tokeny to waluta: płacisz nimi w API i wydajesz je z limitu kontekstu. Dobrze napisany prompt minimalizuje „szum”, a maksymalizuje sygnał: cel, format, ograniczenia i dane wejściowe. Dobra praktyka to kontrola długości, przewidywalny układ oraz testy tokenowe na docelowym modelu.
Jak skracać prompty bez utraty treści? (checklista)
- Usuń „uprzejmości” i powtórzenia (model nie potrzebuje motywacji).
- Zamień długie opisy na wymagania punktowe.
- Przenieś stałe reguły do krótkiej sekcji „Zasady”.
- Używaj formatów, które kompresują informację:
- listy,
- krótkie klucze (
cel:,format:,ograniczenia:), - tabele, jeśli dane są powtarzalne.
- Jeśli masz długi kontekst, rozważ RAG zamiast wklejania wszystkiego.
Mini-reguła: jeśli zdanie nie zmienia odpowiedzi, usuń je.
Jak formatować odpowiedź, żeby ograniczać „rozjazdy”? (checklista)
- Pisz: „Zwróć wynik w formacie X” i pokaż 1 przykład.
- Ogranicz długość: „max 8 punktów”, „max 120 słów”.
- Wymuś strukturę nagłówków lub JSON (jeśli potrzebujesz parsowania).
- Dopisz: „Jeśli brakuje danych, napisz ‘BRAK’ zamiast zgadywać”.
Jak tokeny przekładają się na koszty w API?
W rozliczeniach API zwykle płacisz osobno za:
- tokeny wejściowe (prompt + kontekst),
- tokeny wyjściowe (odpowiedź).
Koszt = (liczba tokenów) × (stawka za tokeny), często w przeliczeniu na 1M tokenów.
Praktyczna konsekwencja:
- długi prompt jest drogi zawsze,
- długi output jest drogi „gdy model się rozgada”.
Tip: ustawiaj limity odpowiedzi (np. max_tokens) i testuj, ile tokenów ma Twój typowy kontekst.
Prompt zły vs prompt dobry (2 krótkie przykłady)
Zły (za długi, mało sterowalny):
Napisz mi proszę wszystko o tokenizacji, bardzo dokładnie, z historią, ciekawostkami i przykładami, ale tak żeby było łatwo i prosto, i żeby nie było za długie. I dodaj też kod i RAG i koszty.
Dobry (krótki, sterowalny):
Cel: wyjaśnij tokenizację w LLM dla juniorów.
Wymagania: 6 sekcji, każda 3–5 punktów, max 1200 słów.
Dodaj: 1 tabela BPE/WordPiece/Unigram, 1 snippet Pythona do liczenia tokenów.
Zakaz: lania wody, bez historii.
Różnica: w „dobrym” promptcie model ma jasny cel, format i limity — czyli mniejsze ryzyko, że „popłynie” tokenowo.
Tokenizacja a RAG — jak chunking i overlap ratują kontekst?
W RAG tokenizacja ma znaczenie podwójnie: wpływa na koszt generacji i na to, jak dzielisz dokumenty na fragmenty do wyszukiwania. Chunking to sztuka krojenia tekstu tak, by fragmenty były semantycznie spójne, a jednocześnie mieściły się w oknie kontekstu. Overlap (nakładka) pomaga nie zgubić sensu na granicach.
Co to jest chunking i overlap — prosto i praktycznie?
- Chunking: dzielenie dokumentu na kawałki (np. 300–800 tokenów).
- Overlap: powtórzenie końcówki/początku między chunkami (np. 50–150 tokenów), by zdania „przechodziły” przez granice.
Bez overlapu model może dostać fragment urwany w połowie myśli, co psuje odpowiedź.
Jak dobrać rozmiar chunków do limitu tokenów?
Praktyczny schemat:
- Zostaw budżet na prompt i instrukcje (np. 400–800 tokenów).
- Zostaw budżet na odpowiedź (np. 300–1200 tokenów).
- Reszta to miejsce na kontekst z RAG (np. 2–6 chunków).
Jeśli model ma „małe okno”, chunk musi być mniejszy. Jeśli okno jest duże, nadal nie przesadzaj: zbyt duże chunki pogarszają trafność retrievalu.
Jakie są 3 heurystyki dzielenia tekstu?
- Po nagłówkach i sekcjach
- najlepsze dla artykułów, dokumentacji, notatek.
- Po zdaniach (lub akapitach)
- dobre dla tekstu ciągłego; kontrolujesz długość tokenową.
- Mieszane: nagłówki + zdania + limity tokenów
- najbardziej praktyczne: trzymasz strukturę i pilnujesz budżetu.
Tip: dziel najpierw logicznie (nagłówki), a dopiero potem docinaj tokenowo.
Jak policzyć tokeny i sprawdzić, jak tokenizer tnie tekst?
Nie da się „zgadywać” tokenów niezawodnie — trzeba je policzyć. Różne modele mają różne tokenizery i słowniki, więc ten sam tekst może kosztować różną liczbę tokenów. Najlepsza praktyka to mieć mały skrypt, który liczy tokeny dla Twojego modelu, i używać go przy projektowaniu promptów, chunkingu i budżetu kosztów.
Jak użyć tiktoken w Pythonie? (przykład)
Instrukcja uruchomienia:
- Zainstaluj:
pip install tiktoken - Uruchom skrypt:
# pip install tiktoken
import tiktoken
def count_tokens(text: str, encoding_name: str = "cl100k_base") -> int:
enc = tiktoken.get_encoding(encoding_name)
return len(enc.encode(text))
def show_tokens(text: str, encoding_name: str = "cl100k_base") -> None:
enc = tiktoken.get_encoding(encoding_name)
token_ids = enc.encode(text)
tokens = [enc.decode([tid]) for tid in token_ids]
print(f"Tekst: {text!r}")
print(f"Liczba tokenów: {len(token_ids)}")
print("Tokeny:", tokens)
if __name__ == "__main__":
samples = [
"Zażółć gęślą jaźń.",
"Rzeczpospolitej",
"AI-owy promptować 2025-12-14",
]
for s in samples:
show_tokens(s)
print("-" * 40)
Ważne: nazwa encodingu zależy od ekosystemu i modelu. Jeśli używasz konkretnego API/modelu, dopasuj encoding zgodnie z jego dokumentacją.
Jak użyć Hugging Face tokenizers/transformers? (przykład)
Instrukcja uruchomienia:
- Zainstaluj:
pip install transformers tokenizers - Uruchom:
# pip install transformers tokenizers
from transformers import AutoTokenizer
def inspect(text: str, model_name: str) -> None:
tok = AutoTokenizer.from_pretrained(model_name, use_fast=True)
enc = tok(text, add_special_tokens=True)
input_ids = enc["input_ids"]
tokens = tok.convert_ids_to_tokens(input_ids)
print(f"Model: {model_name}")
print(f"Tekst: {text!r}")
print(f"Liczba tokenów: {len(input_ids)}")
print("Tokeny:", tokens)
print("-" * 40)
if __name__ == "__main__":
text = "Zażółć gęślą jaźń. Kwiecień2025 AI-owy."
# Podmień na tokenizer zgodny z Twoim modelem:
inspect(text, "bert-base-multilingual-cased")
Czemu liczenie tokenów zależy od tokenizera/modelu?
Bo „token” nie jest uniwersalny. To produkt uboczny:
- wybranej metody (BPE/WordPiece/Unigram/byte-level),
- konkretnego słownika,
- ustawień (np. tokeny specjalne, template czatu).
Dlatego: licz tokeny zawsze na docelowym modelu, szczególnie jeśli optymalizujesz koszty i chunking.
Najczęstsze mity o tokenizacji — co ludzie mylą najczęściej?
Tokenizacja brzmi prosto, ale jest pełna intuicyjnych pułapek. Najczęstszy problem to mylenie tokenów ze słowami oraz przekonanie, że liczba tokenów da się przewidzieć „na oko”. Poniższe mity warto znać, bo wpływają na budżet, jakość i debugowanie zachowania LLM.
Jakie są mity i jak je prostować? (6–10)
- Mit 1: „1 token = 1 słowo.”
Nie. Token może być fragmentem słowa, znakiem albo bajtem. - Mit 2: „Polski zawsze ma więcej tokenów niż angielski.”
Często tak bywa (morfologia, diakrytyki), ale zależy od słownika i domeny tekstu. - Mit 3: „Jeśli skrócę prompt o 30% znaków, to skrócę tokeny o 30%.”
Niekoniecznie. Tokeny nie rosną liniowo ze znakami. - Mit 4: „Tokeny specjalne nie mają znaczenia w praktyce.”
Mają, szczególnie w czacie i w fine-tuningu — mogą zmieniać zachowanie modelu. - Mit 5: „Tokenizer to detal — mogę użyć innego.”
Nie. Tokenizer jest częścią kontraktu wejścia modelu. - Mit 6: „Byte-level zawsze jest gorsze.”
Nie. Jest niezawodne (brak OOV), ale czasem mniej „ładne” dla języków z diakrytykami. - Mit 7: „Więcej tokenów = lepsza odpowiedź.”
Nie. Często to tylko więcej szumu i kosztu. Liczy się informacja, nie długość. - Mit 8: „W RAG wystarczy kroić po 1000 znaków.”
Lepiej kroić tokenowo lub semantycznie; znaki to słaby proxy dla budżetu kontekstu.
Co warto zapamiętać?
Tokenizacja to jeden z tych elementów, które „nie wyglądają na ważne”, dopóki nie zaczniesz płacić za API, walczyć z limitem kontekstu albo debugować RAG. W praktyce to ona decyduje, jak efektywnie pakujesz informację do modelu i jak stabilnie dostajesz odpowiedzi. Oto najkrótszy zestaw wniosków do codziennego użycia.
- Token to jednostka techniczna, nie słowo ani pojęcie.
- Zawsze licz tokeny na docelowym tokenizerze (model ≠ „ogólny LLM”).
- Polskie diakrytyki, odmiana i hybrydy typu „AI-owy” potrafią zwiększać liczbę tokenów.
- Tokeny specjalne (BOS/EOS/PAD/SEP + role czatu) realnie wpływają na zachowanie i koszt.
- W promptach wygrywa: krótko, strukturalnie, z limitami.
- Koszt w API to zwykle: tokeny wejścia + tokeny wyjścia. Limituj oba.
- W RAG lepsze są chunki semantyczne + overlap niż „cięcie na znaki”.
- Jeśli model „gubi sens”, sprawdź: cięcie tokenowe, chunking, template czatu.
- Tokenizacja to część E2E pipeline — warto ją traktować jak narzędzie diagnostyczne.
FAQ
- Czym różni się token od słowa?
Słowo to jednostka językowa, a token to jednostka techniczna tokenizera. Token może być całym słowem, fragmentem słowa, znakiem interpunkcyjnym albo elementem zapisu bajtowego. Dlatego długość tekstu w tokenach bywa zaskakująca. - Dlaczego polski często ma więcej tokenów niż angielski?
Polski ma bogatą odmianę i długie formy fleksyjne, a do tego diakrytyki. Jeśli słownik tokenizera nie ma „gotowych” kawałków dla rzadkich form, tekst częściej tnie się na drobniejsze subwordy. To zwiększa tokeny, ale nie jest regułą absolutną. - Co jest lepsze: BPE czy WordPiece?
To zależy od modelu i jego ekosystemu. BPE jest bardzo popularne w LLM, WordPiece często spotkasz w modelach klasy BERT. Dla użytkownika najważniejsze jest to, by używać tokenizera zgodnego z modelem — nie mieszać ich. - Czy tokeny specjalne naprawdę mają znaczenie w czacie?
Tak. Tokeny ról i znaczniki granic wiadomości wpływają na to, co model uzna za instrukcję, a co za treść. Mają też znaczenie dla liczenia tokenów i limitu kontekstu, bo „niewidoczne” znaczniki też zajmują miejsce. - Jak tokeny wpływają na koszty korzystania z API?
Koszt zwykle rośnie z liczbą tokenów wejścia i wyjścia. Długi kontekst i rozgadany output potrafią podnieść rachunek bardziej niż liczba zapytań. Dlatego warto skracać prompty, ustawiać limity odpowiedzi i mierzyć tokeny. - Ile tokenów mogę zmieścić w kontekście modelu?
To zależy od konkretnego modelu i jego okna kontekstu. Dodatkowo część kontekstu „zjadają” instrukcje systemowe i format czatu. Najpewniej jest policzyć tokeny realnej rozmowy/kontekstu na docelowym tokenizerze. - Jak najprościej policzyć tokeny dla mojego tekstu?
Użyj biblioteki zgodnej z ekosystemem: np. tiktoken albo tokenizera z Hugging Face. Wystarczy kilka linijek kodu, by policzyć długość i podejrzeć, jak tekst został pocięty. To najlepszy sposób, by przestać zgadywać.
1 komentarz do “Tokenizacja w LLM: 11 zasad + przykłady”