
Tokenizacja w LLM: 11 zasad + przykłady
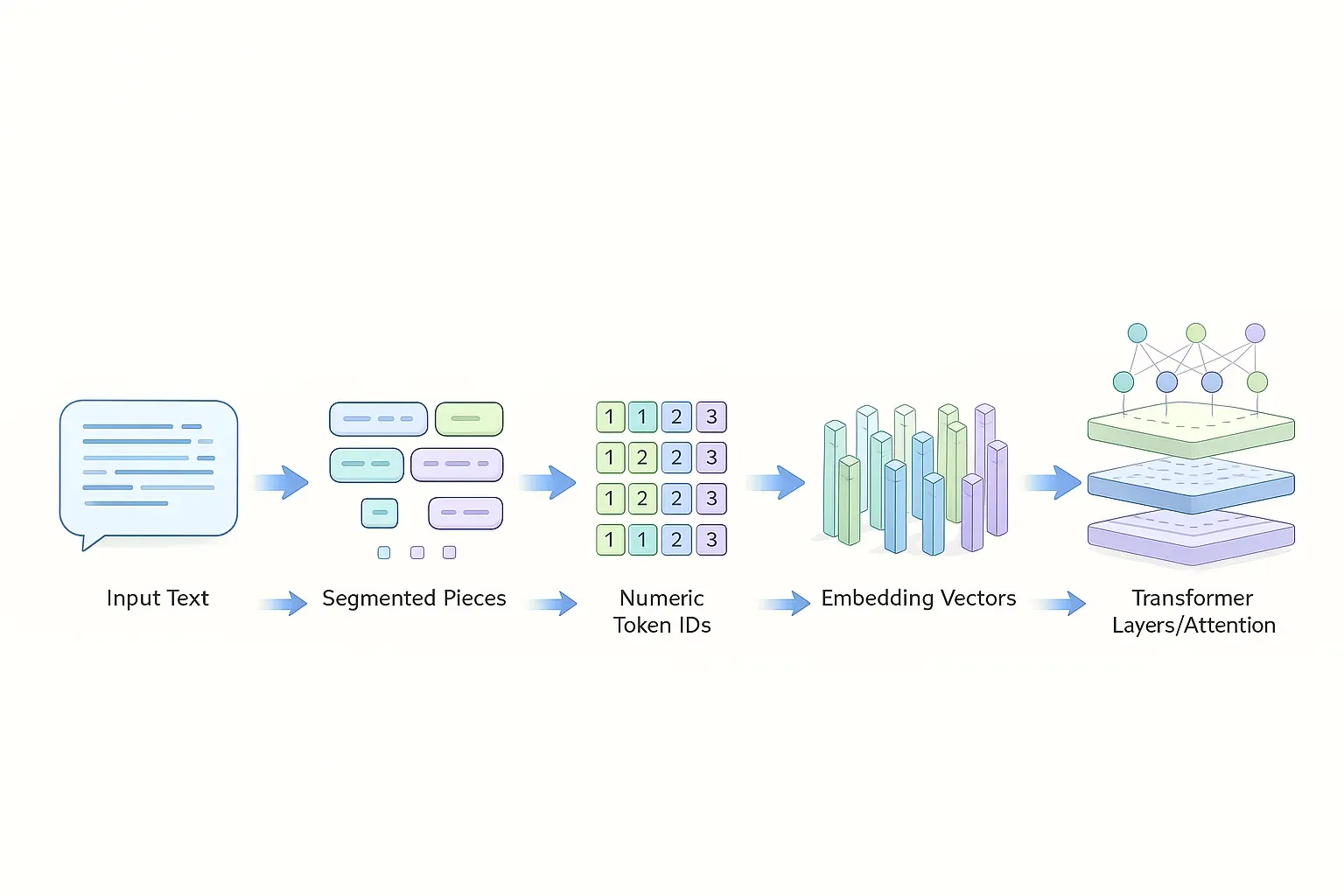
Tokenizacja to proces zamiany tekstu na ciąg identyfikatorów (ID), które model potrafi przetwarzać. Token nie musi być słowem — często jest fragmentem słowa, znakiem interpunkcyjnym lub częścią zapisu bajtowego. Jest kluczowa, bo decyduje o kosztach, limicie kontekstu, jakości generacji i o tym, jak model „widzi” język (także polski). Dlaczego w ogóle istnieje tokenizacja w modelach … Dowiedz się więcej