Jak działa RAG? 5 kroków architektury, które decydują
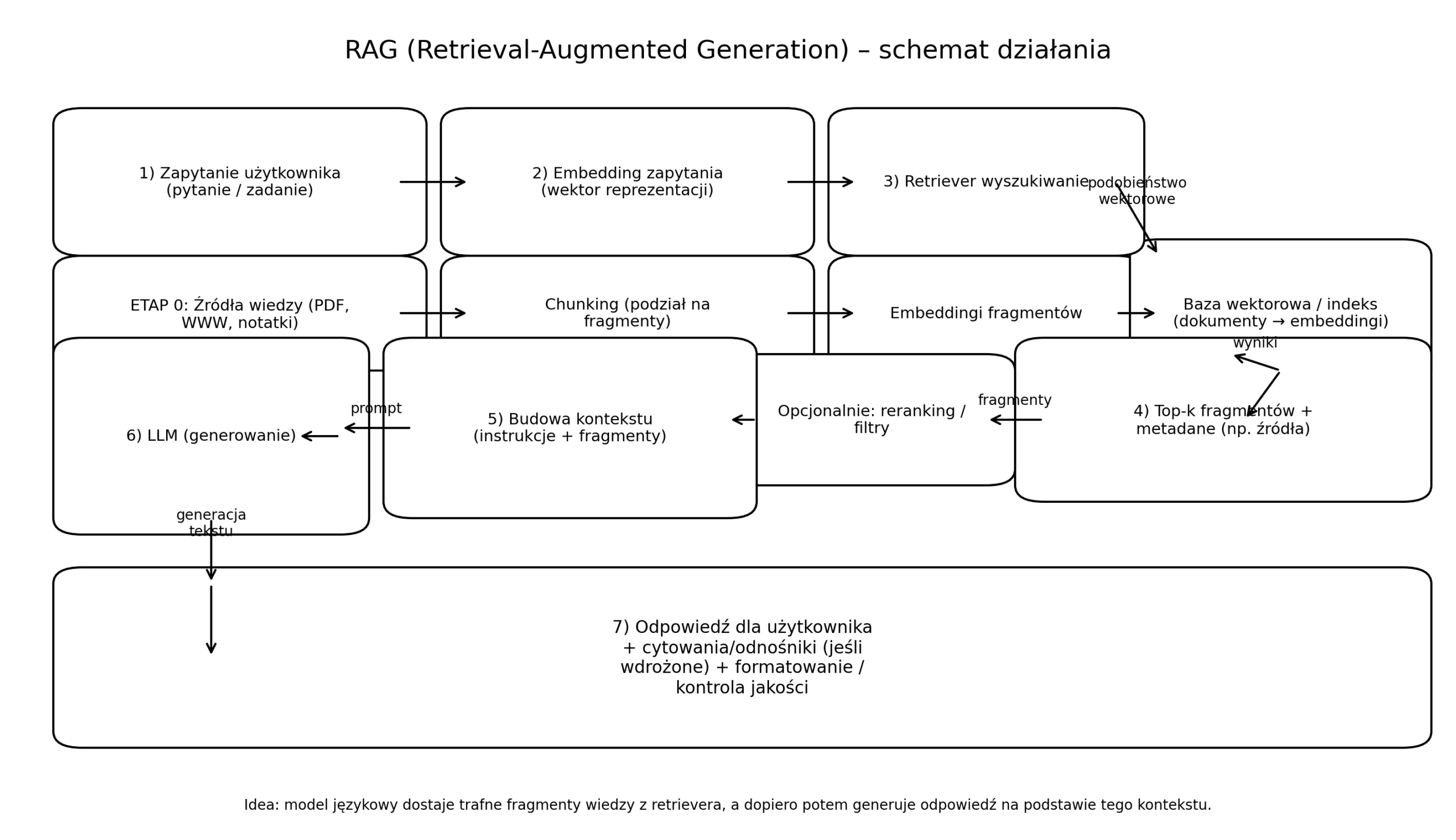
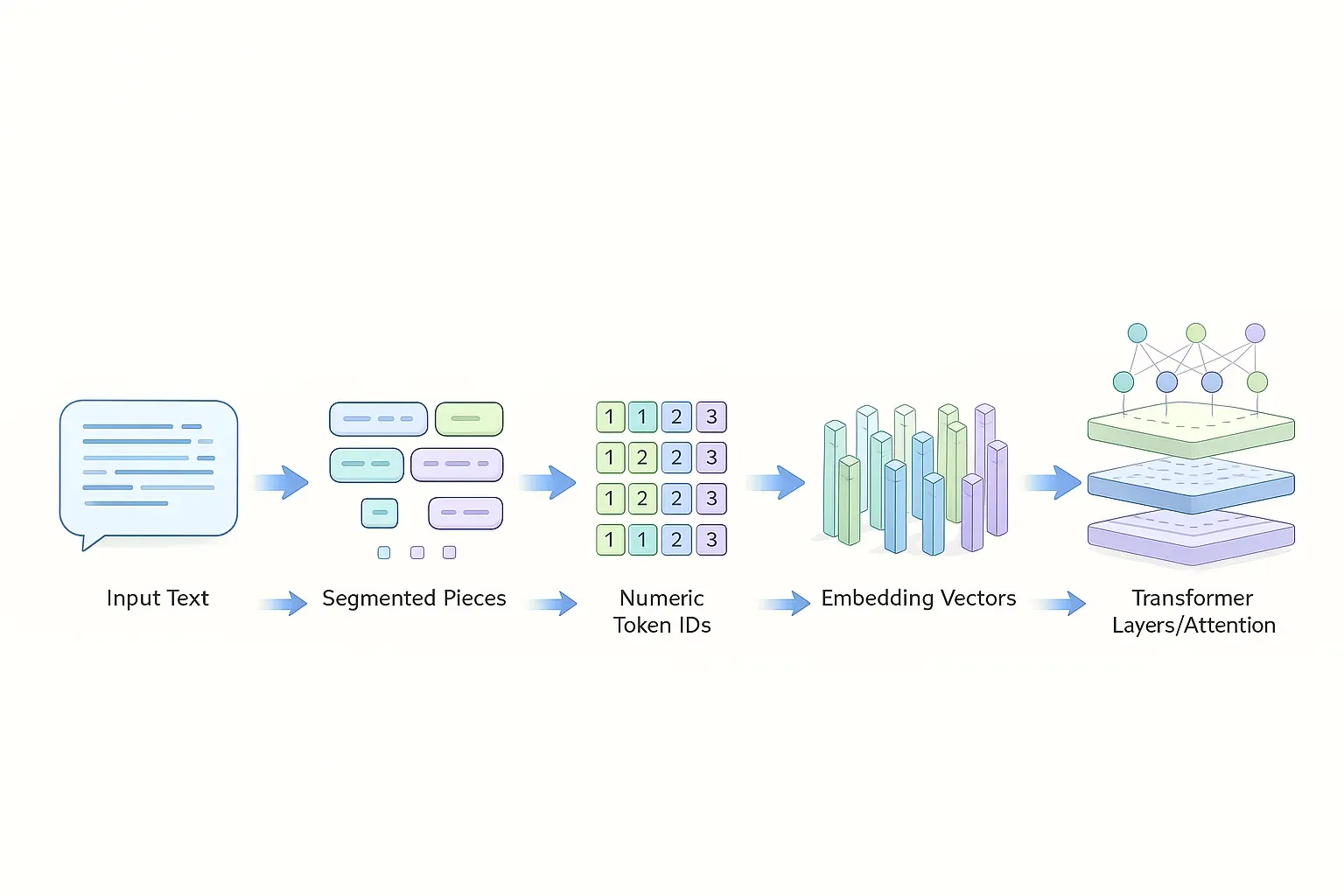
RAG działa tak, że zanim LLM odpowie, system najpierw wyszukuje w zewnętrznej bazie wiedzy najbardziej pasujące fragmenty tekstu. Zapytanie i dokumenty są zamieniane na embeddingi (wektory), retriever wybiera top-k chunków, a potem LLM dostaje prompt z kontekstem i generuje odpowiedź „uziemioną” w źródłach. Jak wygląda ogólna architektura RAG? RAG to architektura „z pamięcią zewnętrzną”: LLM … Dowiedz się więcej