

Sztuczna inteligencja co to jest?
Sztuczna inteligencja (AI) to dziedzina informatyki ukierunkowana na tworzenie systemów wykonujących zadania kojarzone z ludzką inteligencją: uczenie się, rozumowanie, planowanie, percepcję i komunikację. Ujęcia instytucjonalne podkreślają funkcjonalny charakter AI — zdolność systemów technicznych do odbioru danych ze środowiska, ich przetwarzania i działania w celu osiągnięcia konkretnego celu. Parlament Europejski definiuje AI przez pryzmat „ludzkopodobnych” zdolności (reasoning, learning, planning, creativity) oraz pętlę percepcja–decyzja–akcja.
W ujęciu akademickim AI bywa rozumiana jako badanie inteligentnych agentów — programów (lub robotów), które odbierają percepcje (percepts), działają w środowisku (actions) i maksymalizują miarę sukcesu. To podejście porządkuje zarówno algorytmy regułowe, jak i uczenie maszynowe oraz planowanie. Russell i Norvig uczynili z „racjonalnego agenta” motyw przewodni nowoczesnego podręcznika AI.
Podstawowe definicje i rozróżnienia
AI vs. ML vs. DL (w 1 zdaniu)
- AI — „parasol” metod i systemów osiągających inteligentne zachowania.
- ML (machine learning) — metody uczące się na danych (modele statystyczne, uczone na przykładach).
- DL (deep learning) — podzbiór ML oparty na głębokich sieciach neuronowych.
W literaturze filozoficznej (SEP) definiowanie AI obejmuje zarówno historię, jak i filozofię pola, a także spory o granice pojęcia.
Dwa przydatne spojrzenia na AI
- AI jako pole badań i technologii (informatyka + kognitywistyka + logika + neuro): tworzymy systemy „inteligentne” w sensie funkcjonalnym. (Por. SEP i ujęcia logiczne w AI).
- AI jako inteligentne agenty: agent odbiera bodźce (sensors), aktualizuje stan (pamięć), wybiera działanie względem funkcji celu (utility). Ten formalizm porządkuje praktykę od reguł, przez ML, po planowanie i RL.
Jak to działa? Rama pojęciowa i mechanika
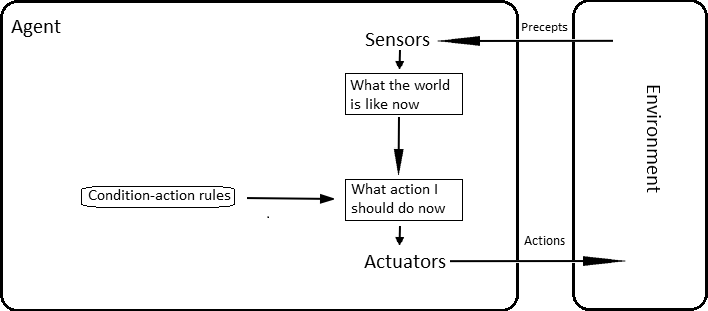
Intuicja (schemat pętli agenta)
AI można ująć jako pętlę przetwarzania informacji: dane → reprezentacje → decyzje/akcje → sprzężenie zwrotne. W wersji agentowej: percepcja → aktualizacja stanu → wybór akcji (maksymalizacja miary sukcesu) → działanie w środowisku. Ilustrują to rozdziały o agentach (refleksyjnych, celowych, użytecznościowych, uczących się).

Grafika (CC / public domain):
Tytuł: „Learning agent — wariant pętli agenta”
Źródło i licencja: IntelligentAgent-Learning.svg, Wikimedia Commons, autor Pduive23, na podstawie Russell & Norvig — CC0/Public domain (wersja SVG).
URL źródła: File:IntelligentAgent-Learning.svg (Wikimedia Commons)
Alt: „Schemat inteligentnego agenta z modułami: uczący się, krytyk, elementy wiedzy i wybór działań.” Wikimedia Commons
Mechanika w 7 krokach
- Problem i miara sukcesu. Przykład: wykrywanie spamu; metryki: F1, recall≥0,90. (Por. przewodniki oceny modeli w scikit-learn).
- Dane. Przykłady z etykietami; podział train/valid/test.
- Model. Od regresji i drzew decyzji po sieci głębokie (CNN, Transformer).
- Uczenie. Minimalizacja straty (np. logloss), optymalizacja (SGD/Adam).
- Ewaluacja. Accuracy, precision/recall, F1, ROC AUC, walidacja krzyżowa. (Zob. dokumentację metryk).
- Wdrożenie. API/edge, rejestr modeli, monitorowanie dryfu. NIST AI RMF zaleca zarządzanie ryzykiem na całym cyklu życia.
- Zarządzanie ryzykiem. Prywatność, bezpieczeństwo, zgodność — w UE prym wyznacza AI Act i praktyki DPIA (ocena skutków dla ochrony danych).
Symboliczne a uczące się: od logiki do neurosymboliczności
Podejścia symboliczne (logika, systemy reguł, wnioskowanie) dobrze reprezentują wiedzę jawną i umożliwiają kontrolowane wnioskowanie, natomiast uczące się (ML/DL) świetnie dopasowują wzorce z danych. Współczesne przeglądy wskazują na neurosymboliczne łączenie paradygmatów: większa interpretowalność i możliwość korzystania z wiedzy eksperckiej przy zachowaniu jakości predykcyjnej.
Klasyfikacja i przykłady zastosowań
Przekrojowa mapa zastosowań
- Sektor publiczny i edukacja: asystenci QA/FAQ 24/7, dostępność informacji, skrócenie czasu obsługi. (Raporty EPRS/Parlamentu Europejskiego omawiają szanse i zagrożenia).
- Medycyna: klasyfikacja obrazów (RTG, MRI), triage — w UE diagnostyka to zastosowanie wysokiej wagi.
- Przemysł/IoT: predykcja awarii, optymalizacja energii; edge AI ogranicza opóźnienia kosztem trudniejszego utrzymania. (EPRS).
- Biznes cyfrowy: rekomendacje, scoring, asystenci; dokumentacje inżynierskie uczulają na różnice AI/ML/DL i metryki jakości. (Zob. scikit-learn metryki).
Mini-case A (szkoła → FAQ-bot)
- Dane: ~4 000 pytań/odpowiedzi z regulaminów i ogłoszeń.
- Model: RAG (retrieval-augmented QA) + reguły (wariant neurosymboliczny).
- Efekt pilotażowy: ~68% pytań rozwiązanych bez kontaktu z sekretariatem; CSAT 4,3/5; czas odpowiedzi −80%. (Przykład dydaktyczny — scenariusz typowego wdrożenia; wartości ilustracyjne).
Mini-case B (e-commerce → rekomendacje)
- Model: Learning-to-Rank (cechy + embeddingi produktu).
- Efekt A/B (N≈50 000 sesji): CTR +12%, średnia wartość koszyka +6%. (Przykład dydaktyczny).
Mini-case C (fabryka → wizyjna kontrola jakości)
- Model: CNN (segmentacja), próg alarmu: recall ≥0,95.
- Wynik: recall 0,96, precision 0,88; fałszywe alarmy ograniczane regułami biznesowymi. (Przykład dydaktyczny).
Mini-case D (zdrowie → klasyfikacja opisów objawów)
- Model: klasyfikator tekstu (Transformer) + filtr bezpieczeństwa.
- Wynik: AUC 0,89; ograniczenia: brak decyzji klinicznych bez lekarza, wymogi prawne i etyczne (SEP, EPRS).
Pętla życia systemu AI (od koncepcji do produkcji)
Uproszczony pipeline produkcyjny: Źródła danych (logi, obrazy, tekst) → ETL/feature store → trening ML/DL → walidacja (metryki) → rejestr modeli → wdrożenie (API/edge) → monitoring (dryf, bezpieczeństwo) → rekonekcja danych i retraining. Prace przeglądowe oraz EPRS podkreślają ciągły charakter cyklu życia i sprzężenia zwrotnego.
Alternatywne grafiki CC (opcjonalne):
• Simple reflex agent (public domain) — diagram agenta refleksyjnego. Alt: „Schemat prostego agenta refleksyjnego z regułami if–then.” Wikimedia Commons
• Agent with body and controller (David Poole, Alan Mackworth) — diagram agenta z kontrolerem. Alt: „Agent z modułem percepcji i sterowania.” (Sprawdź licencję przed osadzeniem). Wikimedia Commons
Metryki, ewaluacja i pułapki
Metryki klasyfikacji (najczęstsze)
- Accuracy (trafność),
- Precision / Recall / F1,
- ROC AUC, PR AUC,
- raport z
classification_report(scikit-learn).
Uwaga na niezbalansowane klasy: accuracy może mylić — preferuj F1, PR AUC i analizę progów decyzyjnych. (Dokumentacja metryk scikit-learn).
Typowe błędy
- Mylenie AI z ML/DL → projekty bez celu i miar.
- Overfitting → świetne wyniki „na papierze”, słaba generalizacja.
- Leakage (wyciek informacji) → cechy „podglądają” etykietę.
- Hallucinations (LLM) → wymyślanie faktów; łagodzone przez RAG i cytaty.
- Bezpieczeństwo: prompt injection, data poisoning, model stealing. (Zob. NIST AI RMF — funkcje GOVERN/MAP/MEASURE/MANAGE).
Regulacje i etyka
Kierunki w UE
AI Act to pierwsze kompleksowe przepisy dotyczące AI, oparte na podejściu risk-based (np. systemy wysokiego ryzyka). Wraz z tym towarzyszącym ekosystemem wytycznych wzmacnia bezpieczeństwo i prawa obywateli.
DPIA (ocena skutków dla ochrony danych) jest wymagana, gdy przetwarzanie może powodować wysokie ryzyko dla praw i wolności osób — w szczególności przy nowych technologiach i zautomatyzowanym profilowaniu. (Wytyczne UODO i zasoby GDPR.eu zawierają praktyczne listy kontrolne).
Ramy zarządzania ryzykiem
NIST AI RMF (USA) to dobrowolny, szeroko przyjmowany standard praktyk: GOVERN–MAP–MEASURE–MANAGE w całym cyklu życia systemu. Służy włączaniu wymagań zaufania (m.in. bezpieczeństwo, rzetelność, prywatność) do projektowania i eksploatacji.
Etyka i filozofia AI
W ujęciu Stanford Encyclopedia of Philosophy (SEP) kwestie etyczne obejmują m.in. manipulację, godność, autonomię, odpowiedzialność za decyzje oraz projektowanie artefaktów symulujących inteligencję. To tło pomaga tłumaczyć wymogi prawne i społeczne wobec AI.
Praktyczny start: checklista + mały projekt (SMS spam)
Checklista startowa (dla szkoły/studiów/juniora)
- Zdefiniuj problem i metryki (np. F1≥0,90; recall spamu ≥0,92).
- Zbierz dane i sporządź data card (pochodzenie, prawa, bias).
- Podziel zestaw na train/valid/test (np. 70/15/15, stratyfikacja).
- Zacznij od baseline (regresja logistyczna, drzewo), dopiero potem DL.
- Waliduj i loguj eksperymenty (np. MLflow/W&B).
- Hard negatives dla poprawy recall/precision.
- Wdrożenie: prosty endpoint (FastAPI/Flask), parametry progów.
- Monitoring i ryzyka: dryf danych, dzienniki audytowe, polityka PII zgodna z GDPR/DPIA. (Wsparcie: NIST AI RMF, UODO).
Snippet (Python, klasyfikacja SMS spam/ham)
Dane: UCI SMS Spam Collection — zbiór edukacyjny, publicznie dostępny. archive.ics.uci.edu
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
df = pd.read_csv("sms.csv") # kolumny: text,label (spam/ham)
X_train, X_test, y_train, y_test = train_test_split(
df["text"], df["label"], test_size=0.2, stratify=df["label"], random_state=42
)
pipe = Pipeline([
("tfidf", TfidfVectorizer(min_df=3, ngram_range=(1,2))),
("clf", LogisticRegression(max_iter=200))
])
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
print(classification_report(y_test, y_pred))
Dokumentacja classification_report (precision/recall/F1) w scikit-learn: scikit-learn.org
Najczęstsze pytania (FAQ)
1) Czym różni się AI od ML i DL?
AI to parasol dla metod tworzących inteligentne zachowania; ML to zbiór metod uczonych na danych; DL to ML oparte na głębokich sieciach. (Por. SEP).
2) Jakie są główne rodzaje AI?
Najczęściej wyróżnia się wąską AI (Narrow) do konkretnych zadań oraz ogólną AI (AGI) — hipotetyczną, o elastyczności poznawczej człowieka. (EPRS o „general-purpose AI”).
3) Czy AI „zastąpi” ludzi?
AI przekształca strukturę pracy: automatyzuje rutynę i wzmacnia decyzje; rośnie popyt na kompetencje hybrydowe, a dyskusje etyczne i rynkowe trwają. (EPRS).
4) Jak mierzyć „dobroć” modelu?
W zależności od zadania: klasyfikacja — precision/recall/F1/ROC AUC; regresja — MAE/MSE/R²; generatywne — BLEU/ROUGE/oceny eksperckie. (scikit-learn).
5) Chmura czy edge?
Edge ogranicza opóźnienia i koszty transferu, ale utrudnia trening/utrzymanie; chmura daje skalowalność. (EPRS).
6) Czy AI jest bezpieczna i zgodna z prawem?
Zależy od projektu; wymagane są mechanizmy prywatności, transparentności i oceny ryzyka. W UE obowiązuje AI Act, DPIA dla przetwarzania wysokiego ryzyka.
7) Skąd brać rzetelną wiedzę?
Podręczniki (Russell & Norvig), SEP, raporty EPRS, dokumentacje narzędzi i standardów (NIST AI RMF).
8) Czy zawsze potrzebny jest deep learning?
Nie — baseline z klasycznych metod bywa lepszy przy małej skali lub prostym celu; DL warto porównywać dopiero po ustaleniu punktu odniesienia. (Praktyki ewaluacyjne).
Dyskusje i kontrowersje
- Transparentność i wyjaśnialność vs. jakość predykcji: DL osiąga wysoką skuteczność kosztem interpretowalności; nurty neurosymboliczne proponują kompromisy.
- Odpowiedzialność i sprawczość: komu przypisywać odpowiedzialność za decyzje AI? (Analizy SEP).
- Zagrożenia dla rynku pracy, demokracji i bezpieczeństwa: EPRS wymienia zarówno szanse, jak i ryzyka systemowe.
- Standaryzacja dobrych praktyk: NIST AI RMF przyjęty jako de facto referencja zarządzania ryzykiem (poza UE).
Słowa kluczowe LSI (semantyczne)
AI definicja; uczenie maszynowe; deep learning; inteligentne agenty; metryki klasyfikacji; ROC AUC; explainable AI; neurosymbolic AI; edge AI; model drift; RAG; DPIA; AI Act; NIST AI RMF; etyka AI.
Tabela: AI vs ML vs DL (skrót porównawczy)
| Właściwość | AI | ML | DL |
|---|---|---|---|
| Zakres | Parasol metod inteligentnych | Podzbiór AI | Podzbiór ML |
| Cel | Zachowania inteligentne | Uczenie z danych | Uczenie z głębokich sieci |
| Dane | Różne (w tym wiedza symboliczna) | Wymagane | Zwykle duże zbiory |
| Przykłady | Planowanie, wnioskowanie, RL | SVM, drzewa, regresja | CNN, RNN, Transformer |
| Plusy | Elastyczność konceptualna | Efektywność przy mniejszych danych | Najlepsze wyniki dla złożonych zadań |
| Minusy | Ogólność pojęcia | Wymaga inżynierii cech | Interpretowalność, koszty obliczeń |
(Oparcie definicyjne: SEP; rama agentowa: Russell & Norvig). plato.stanford.edu+1
Zobacz też (linki powiązane)
- Decode The Future: RAG (Retrieval-Augmented Generation): czym jest i jak wdrożyć? — architektura, metryki, bezpieczeństwo.
- Decode The Future: LLM: co to jest i jak działa?
- NIST: AI Risk Management Framework. NIST
- EPRS/Parlament UE: [What is AI and how is it used?] oraz [EU AI Act]. Parlament Europejski+1
Źródła
- European Parliament — „What is artificial intelligence and how is it used?” (definicja i przykłady). Parlament Europejski
- European Parliament — „EU AI Act: first regulation on artificial intelligence” (regulacje, podejście risk-based). Parlament Europejski
- Stanford Encyclopedia of Philosophy — „Artificial Intelligence” (historia, definicje). plato.stanford.edu
- Stanford Encyclopedia of Philosophy — „Ethics of AI and Robotics” (ramy etyczne). plato.stanford.edu
- Russell, Norvig — AIMA (Intelligent Agents, rozdz. 2) — PDF (ramy agentowe). aima.cs.berkeley.edu
- NIST — AI Risk Management Framework (GOVERN–MAP–MEASURE–MANAGE). NIST+1
- scikit-learn — dokumentacja metryk i
classification_report. scikit-learn.org+1 - UCI — „SMS Spam Collection” (zbiór danych edukacyjny). archive.ics.uci.edu
- Przeglądy neurosymboliczne (arXiv). arXiv+2arXiv+2
- UODO (PL) — o obowiązku przeprowadzania DPIA (GDPR art. 35). UODO