
An LLM (Large Language Model) is an AI system built on the transformer architecture that processes, understands, and generates human-like text by predicting the next token in a sequence. Trained on trillions of tokens from books, websites, and code repositories, LLMs such as GPT-4, Claude, and Llama 3 power applications ranging from conversational assistants and code generation to scientific research and education. This guide explains how they work, what their limitations are, and how to start using them in practice.
Large Language Models
Large language models have become the defining technology of the 2020s. In barely five years the field has moved from GPT-2 generating semi-coherent paragraphs to multimodal systems that write production code, summarize medical literature, and pass bar exams. Yet the core question remains surprisingly common: what is an LLM, really, and how does it work under the hood?
This article is a comprehensive, practitioner-oriented guide. It covers the foundational concepts — tokens, embeddings, attention — and then moves through architecture, generation strategies, real-world applications, common pitfalls, and a step-by-step quickstart. Whether you are a junior developer, a product manager evaluating AI vendors, or a curious non-technical reader, you will leave with a solid mental model of what large language models are and how to work with them responsibly.
1. Foundations and Definitions
1.1 From Classic NLP to the Transformer Era
Natural language processing (NLP) has existed as a discipline since the 1950s, but for decades it relied on hand-crafted rules, bag-of-words statistics, and sequential neural networks like RNNs and LSTMs. These systems could classify sentiment, tag parts of speech, and translate short sentences — but they struggled with long-range dependencies. An RNN reading a 500-word paragraph would gradually forget the opening sentences by the time it reached the end.
The breakthrough came in 2017 with the publication of Attention Is All You Need by Vaswani et al. The paper introduced the transformer, a neural network architecture that abandons sequential processing entirely. Instead, it computes relationships between every pair of tokens in a sequence simultaneously through a mechanism called self-attention. This parallelism had two immediate consequences: training became dramatically faster on modern GPUs, and models could capture context over much longer sequences.
Within a year, Google released BERT (2018), which demonstrated that a transformer pre-trained on large corpora could be fine-tuned to beat every existing benchmark in NLP by 10–20 %. OpenAI’s GPT line pushed the idea further — rather than fine-tuning for each task, a single large model could be prompted to perform almost any text task zero-shot. That scaling insight is the foundation of every modern LLM.
1.2 Key Vocabulary: Tokens, Context Windows, Embeddings, and Logits
To understand how an LLM works, you need four core concepts. Without them, discussions about prompt engineering, sampling, or fine-tuning will remain opaque.
Token. A token is the atomic unit a model reads and writes. It is not necessarily a whole word — most LLMs use sub-word tokenization (see section 2.2). The English word “unbelievable” might be split into three tokens: un, believ, able. This lets models handle rare words, misspellings, and multilingual text with a manageable vocabulary (typically 32 K – 100 K tokens).
Context window. The context window is the maximum number of tokens a model can “see” at once — both the input prompt and the generated output combined. GPT-3.5 had a 4 096-token window; GPT-4 Turbo extended this to 128 K. Claude 3.5 Sonnet offers 200 K tokens. Longer windows allow the model to reason over entire books or code repositories, but they increase memory and compute costs quadratically with standard attention.
Embedding. Before the model can process a token it must convert it to a numerical representation — a vector of, say, 4 096 floating-point numbers. This vector lives in a high-dimensional semantic space where similar meanings cluster together. The classic example: the embedding for “king” minus “man” plus “woman” lands near “queen.” Embeddings are the bridge between human language and linear algebra.
Logit. After all transformer layers have processed the input, the model produces a vector of raw scores — one per vocabulary token — called logits. A softmax function converts these into probabilities. The token with the highest logit is the model’s best guess for the next word. Sampling strategies (temperature, top-p) manipulate these probabilities to control creativity.
| Concept | Definition | Example |
|---|---|---|
| Token | Atomic sub-word unit the model reads | “Unbelievable” → un, believ, able |
| Context window | Max tokens the model processes at once | GPT-4 Turbo: 128 K tokens |
| Embedding | Dense vector capturing semantic meaning | “King” − “Man” + “Woman” ≈ “Queen” |
| Logit | Raw output score before softmax | High logit for “cat” after “The pet…” |
2. How It Works — Intuition and Mechanics
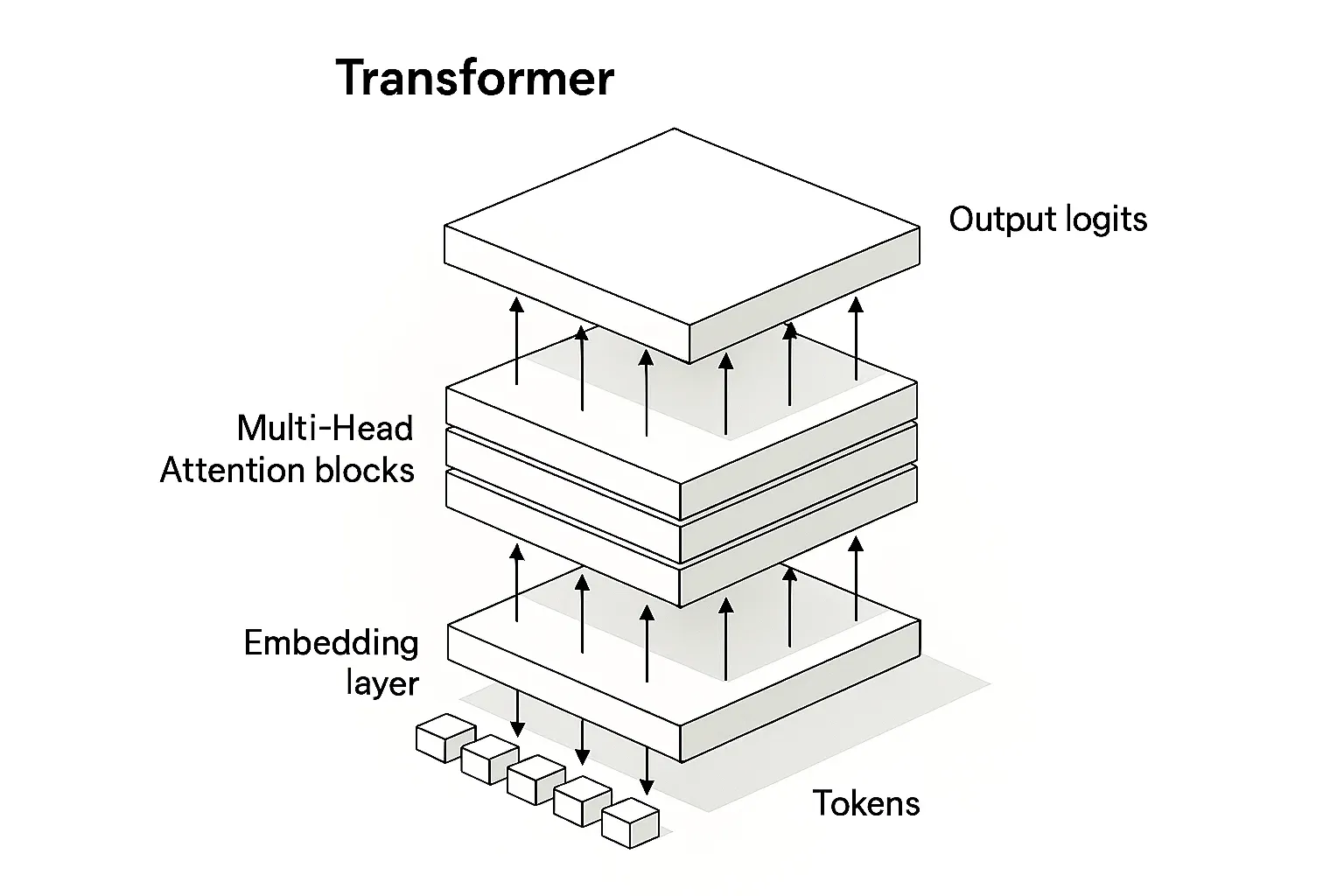
At the highest level an LLM is a next-token predictor. You feed it a sequence of tokens, and it outputs a probability distribution over which token should come next. Repeat this step autoregressively and you get sentences, paragraphs, or entire programs. But the internal machinery is far more interesting than that one-sentence summary suggests.
2.1 The Transformer Architecture: Attention, Multi-Head, and Residuals
The transformer consists of stacked layers, each containing two sub-blocks: a multi-head self-attention block and a feed-forward network. The attention block is where the magic happens.
Self-attention works with three matrices derived from each token’s embedding: Query (Q), Key (K), and Value (V). Think of it as a lookup system: Q is the question (“what context do I need?”), K is the index (“here is what each token offers”), and V is the actual content. The formula is:
Attention(Q, K, V) = softmax(Q KT / √dk) · V
Dividing by √dk prevents dot products from growing too large, which would saturate the softmax. Multi-head attention runs this computation in parallel across multiple “heads” (typically 32–128), each attending to different aspects of the input — one head might focus on syntactic structure while another tracks semantic relationships.
Residual connections add the input of each sub-block directly to its output, creating a shortcut that prevents the vanishing gradient problem. Combined with layer normalization, this lets transformers stack 80+ layers without training instability.
2.2 Tokenization: How Text Becomes Numbers (BPE)
Before a transformer can process text it must convert characters into integer token IDs. The dominant algorithm is Byte-Pair Encoding (BPE). It starts with individual bytes, then iteratively merges the most frequent pair into a new token until the vocabulary reaches a target size (typically 32 K–100 K entries). The result is an efficient compression: common words like “the” get a single token, while rare words are decomposed into familiar sub-parts.
Consider the sentence “What is an LLM?” A BPE tokenizer might produce: [What, ·is, ·an, ·LL, M, ?] (the dot represents a leading space). This sub-word split is why LLMs handle neologisms, typos, and code syntax gracefully — they do not need every string to exist in a fixed dictionary.
2.3 Generation Strategies: Temperature, Top-p, and Beam Search
Once the transformer produces logits for the next token, a decoding strategy decides which token to actually emit. This is where you, as a practitioner, have direct control over the model’s behavior.
Temperature scales the logits before softmax. A temperature of 0.2 sharpens the distribution — the model almost always picks the highest-probability token, producing deterministic, “safe” text. A temperature of 1.0 leaves the distribution unchanged, and values above 1.0 flatten it, introducing more randomness and creative surprise (at the cost of coherence).
Top-p (nucleus sampling) takes a different approach: it includes only the smallest set of tokens whose cumulative probability exceeds a threshold p (commonly 0.9 or 0.95). This dynamically adapts the candidate pool — when the model is confident, only a few tokens qualify; when it is uncertain, many do.
Beam search maintains multiple candidate sequences (beams) in parallel, expanding each at every step and keeping the top-scoring ones. It is excellent for tasks that demand globally optimal sequences, like machine translation, but tends to produce repetitive, “safe” text in open-ended generation.
In practice, many developers combine temperature and top-p. A common production setting for conversational AI is temperature=0.7, top_p=0.95: creative enough to avoid robotic repetition, constrained enough to stay on topic.
# Python — controlling generation parameters
import torch
logits = model(input_tokens) # raw logits
scaled = logits / temperature # sharpen or flatten
probs = torch.softmax(scaled, dim=-1) # convert to probs
next_token = torch.multinomial(probs, num_samples=1) # sample
2.4 Limitations You Must Know
No discussion of LLMs is complete without an honest account of their weaknesses.
Finite context. Even a 200 K-token window has boundaries. Feed the model a 300-page legal contract and it will either truncate or degrade in quality toward the edges of the window.
Hallucinations. LLMs generate statistically plausible text, not verified truth. They confidently cite non-existent papers, invent court cases, and fabricate statistics. In high-stakes domains — medicine, law, finance — hallucinations are not just annoying, they are dangerous.
Compute costs. Training a frontier model costs tens of millions of dollars. Even inference is expensive at scale: serving a model with hundreds of billions of parameters requires clusters of high-end GPUs.
Privacy. Training data often includes personally identifiable information scraped from the web. Models can memorize and regurgitate verbatim passages, raising GDPR and copyright concerns.
3. Real-World Applications and Case Studies
3.1 Where LLMs Deliver Value Today
Conversational assistants. Products like ChatGPT, Claude, and Gemini handle millions of daily queries — from drafting emails to debugging code to planning travel. The key innovation is not just accuracy but interaction quality: LLMs maintain multi-turn conversations, ask clarifying questions, and adapt tone to context.
Code generation. GitHub Copilot, Cursor, and Claude Code autocomplete functions, generate unit tests, and refactor legacy code. Studies show that AI-assisted developers ship features 30–55 % faster on routine tasks, though the gain shrinks for novel architecture decisions.
Research and analysis. Scientists use LLMs to summarize papers, extract structured data from unstructured text, and draft literature reviews. In drug discovery, models identify candidate molecules by predicting protein-ligand interactions from textual descriptions of chemical properties.
Education. Personalized tutoring systems powered by LLMs adapt explanations to a student’s level, generate practice problems on the fly, and provide instant feedback on essays — tasks that previously required one-on-one human tutoring.
3.2 RAG vs. Standalone LLM: When to Combine
Retrieval-Augmented Generation (RAG) is a pattern where the LLM is paired with an external knowledge base. When a user asks a question, a retriever first fetches the most relevant documents (using vector search), then the LLM generates a response grounded in those documents. This dramatically reduces hallucinations and keeps answers current — the knowledge base can be updated daily, while the model itself may have a months-old training cutoff.
A standalone (“naked”) LLM is faster and simpler to deploy, but it is limited to whatever knowledge was baked in during training. Use it for creative writing, brainstorming, and tasks where factual precision matters less. Use RAG when correctness, recency, and traceability are requirements.
3.3 Mini-Case: From Question to Answer — The Request Path
Let’s trace what happens when a user types “What is an LLM?” into a web application powered by a large language model.
Step 1 — Tokenization. The BPE tokenizer converts the string into token IDs: [What, ·is, ·an, ·LL, M, ?].
Step 2 — Embedding lookup. Each token ID is mapped to its embedding vector (e.g., 4 096 dimensions). Positional encodings are added so the model knows the order of tokens.
Step 3 — Transformer forward pass. The embeddings flow through dozens of attention + FFN layers. Attention heads compute relationships: “LLM” and “What” become strongly linked, signaling a definition request.
Step 4 — Logit computation. The final layer outputs a logit vector over the entire vocabulary (~100 K entries). Softmax converts these to probabilities.
Step 5 — Sampling. With temperature=0.7, the model samples from the top of the distribution. It might emit “An” as the first output token. This token is appended to the sequence and the whole process repeats autoregressively.
Step 6 — Delivery. Tokens stream back to the user’s browser via server-sent events. Total latency: typically 200–800 ms to the first token, with subsequent tokens arriving every 20–50 ms.
4. Common Mistakes and Pitfalls
4.1 Bad Prompts, Missing Evaluation, Blind Trust
The single most common mistake beginners make is writing vague prompts. “Write about AI” produces generic filler. “Write a 300-word executive summary of transformer-based LLMs for a CTO audience, focusing on cost and latency trade-offs” produces something useful. Specificity is the first lever of prompt engineering.
The second mistake is skipping evaluation. Without metrics, you have no idea whether your model is improving or regressing. At minimum, track perplexity (how surprised the model is by held-out text), ROUGE or BLEU for summarization/translation tasks, and human ratings on a 1–5 Likert scale for subjective quality.
The third mistake is blind trust. An LLM does not “know” facts — it predicts tokens. Treating its output as ground truth in a medical diagnosis system, a legal brief, or a financial report without human review is an invitation for disaster.
4.2 Security: Jailbreaks, Sensitive Data, and Guardrails
Jailbreaks are adversarial prompts that trick the model into bypassing safety filters — for example, by framing a harmful request as a fictional scenario. Model providers deploy alignment training (RLHF, constitutional AI) to reduce susceptibility, but no system is fully immune.
Data leakage is a real concern when users paste confidential documents into cloud-hosted LLMs. If the provider uses input data for training, sensitive information could resurface in other users’ sessions. Always check the provider’s data retention and training policies.
Guardrails are output-filtering layers that sit between the model and the end user. They can block profanity, flag hallucinated citations, or enforce brand-specific tone guidelines. Think of them as the last line of defense in a production deployment.
1. Cross-check factual claims against authoritative sources.
2. Test edge cases — adversarial prompts, multilingual inputs, extremely long contexts.
3. Measure quality with BLEU, ROUGE, or human evaluation.
4. Deploy guardrails (content filters, citation verification, rate limiting).
5. Monitor production outputs continuously — model behavior can shift with traffic patterns.
5. Getting Started in Practice (Step by Step)
5.1 Quickstart: Local or Cloud, Library, Model, Hardware
The fastest way to experiment with LLMs is to install Hugging Face Transformers and load an open model. Here is the minimal setup:
# 1. Install the library
pip install transformers torch
# 2. Run a simple generation
from transformers import pipeline
generator = pipeline(
"text-generation",
model="meta-llama/Llama-3.2-1B", # lightweight, runs on CPU
device_map="auto" # uses GPU if available
)
result = generator(
"Explain what a large language model is in one paragraph.",
max_new_tokens=150,
temperature=0.7,
top_p=0.95,
do_sample=True
)
print(result[0]["generated_text"])
Hardware considerations: A quantized 7 B-parameter model runs comfortably on a laptop with 16 GB RAM (CPU only, ~2 tokens/sec). A 70 B model needs a GPU with ≥ 48 GB VRAM (e.g., A100) for decent throughput. For cloud inference without managing hardware, providers like OpenAI, Anthropic, and Google offer pay-per-token APIs.
For fully local, offline setups, Ollama provides a one-command install that handles model downloads, quantization, and a local REST API — ideal for privacy-sensitive use cases.
5.2 Evaluation in a Nutshell
Evaluation tells you whether your LLM application actually works. There are three levels:
Automated metrics. Perplexity measures fluency (lower = better). ROUGE measures overlap with reference summaries. BLEU measures n-gram precision in translation. These are fast and cheap, but they do not capture nuance.
A/B testing. Show two prompt variants to real users and measure which produces more helpful, accurate, or engaging responses. This captures user preference directly, but requires traffic and time.
Human-in-the-loop. Expert reviewers score model outputs on dimensions like factual accuracy, relevance, tone, and safety. Expensive, but irreplaceable for high-stakes applications.
5.3 Fine-Tuning with LoRA
Fine-tuning adapts a general-purpose LLM to your specific domain — say, medical records or legal contracts. The naive approach (retraining all parameters) is prohibitively expensive for large models. LoRA (Low-Rank Adaptation) solves this by freezing the base weights and injecting small trainable matrices into each attention layer. Typical LoRA fine-tuning updates less than 1 % of total parameters, reducing GPU memory requirements by 10×.
The workflow: prepare a curated dataset (e.g., 5 000 examples of domain-specific question-answer pairs), configure LoRA rank and alpha, train for 2–5 epochs on a single GPU, and evaluate against a held-out test set. Libraries like peft and trl from Hugging Face make this a few dozen lines of code.
6. The 2026 Landscape: Trends Worth Watching
Longer contexts, cheaper. Techniques like Ring Attention and sparse attention are pushing context windows past 1 million tokens while keeping compute sub-quadratic. By late 2026, million-token windows may be standard even in mid-tier models.
Multimodality as default. Leading models already process text, images, audio, and video within a single architecture. The trend is toward models that reason across modalities natively — reading a chart, hearing a voice memo, and generating a written summary in one step.
Agents and tool use. Rather than just generating text, LLMs increasingly orchestrate tools: browsing the web, executing code, querying databases, and calling APIs. This “agentic” pattern transforms the LLM from a text generator into a general-purpose reasoning engine.
Smaller, specialized models. While frontier labs push toward ever-larger models, a counter-trend favors compact, domain-specific models (1–7 B parameters) that can run on edge devices — phones, IoT sensors, embedded systems — with sub-second latency and no cloud dependency.
Regulation and safety. The EU AI Act entered enforcement in 2025, and similar frameworks are emerging globally. For practitioners, this means mandatory risk assessments, transparency requirements, and documentation for high-risk AI systems — including many LLM applications.
7. Frequently Asked Questions
What is the difference between an LLM and traditional NLP?
Traditional NLP relied on hand-crafted rules, statistical models, and recurrent neural networks, which limited scalability. LLMs use the transformer architecture to process text in parallel, learning patterns from trillions of tokens. This gives them far superior context understanding and generation capabilities.
Does an LLM actually understand language?
No. An LLM simulates understanding through statistical pattern matching. It predicts the most probable next token based on training data, but it has no consciousness, intentionality, or genuine comprehension. Researchers sometimes describe this behavior as a “stochastic parrot.”
How can you reduce LLM hallucinations?
Use Retrieval-Augmented Generation (RAG) to ground responses in external data, apply domain-specific fine-tuning, write prompts that instruct the model to cite sources or admit uncertainty, and deploy guardrails that filter outputs before they reach the user.
What is the difference between temperature and top-p sampling?
Temperature scales the entire probability distribution: lower values (e.g., 0.2) make output more deterministic, higher values (e.g., 1.0) increase randomness. Top-p (nucleus sampling) dynamically selects the smallest set of tokens whose cumulative probability exceeds a threshold p, discarding unlikely tokens regardless of distribution shape.
Can LLMs run offline without an internet connection?
Yes. Open-weight models like Llama 3, Mistral, and Phi-3 can run locally on consumer hardware using frameworks such as Ollama, llama.cpp, or Hugging Face Transformers. A GPU accelerates inference, but CPU-only setups work for smaller quantized models.
When should you combine an LLM with RAG?
Combine when your application requires up-to-date factual accuracy, domain-specific knowledge not present in the training data, or verifiable citations. Use a standalone LLM for creative writing, brainstorming, or tasks where factual precision is less critical.
What is fine-tuning and how does it affect an LLM?
Fine-tuning adapts a pre-trained LLM to a specific domain or task by training it further on a curated dataset. Techniques like LoRA (Low-Rank Adaptation) make this efficient by updating only a small fraction of parameters, reducing compute costs while improving domain performance.
Sources and Further Reading
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30. https://arxiv.org/abs/1706.03762
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. Proceedings of NAACL-HLT 2019. https://arxiv.org/abs/1810.04805
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1–67. https://arxiv.org/abs/1910.10683
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685. https://arxiv.org/abs/2106.09685
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33. https://arxiv.org/abs/2005.11401
Hugging Face. (2024). Transformers documentation. https://huggingface.co/docs/transformers
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., & Lample, G. (2023). LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971. https://arxiv.org/abs/2302.13971
European Commission. (2024). The AI Act. https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
2 thoughts on “What Is an LLM? Large Language Models Explained — A Practical Guide for 2026”